1_5_列表和列表操作#
作者: ZhouLong
创建日期: 2026 年 01 月 13 日
版本: 1.0
浏览量:
1.列表的基本概念#
列表(List) 是Python中最常用的数据结构之一,它是一个有序、可变的序列,可以存储任意类型的元素。
# 创建列表
empty_list = [] # 空列表
numbers = [1, 2, 3, 4, 5] # 整数列表
mixed_list = [1, "hello", 3.14, True] # 混合类型列表
nested_list = [[1, 2], [3, 4]] # 嵌套列表
print(type(numbers)) # <class 'list'>
列表中的每个值都有对应的位置值,称之为索引,第一个索引是 0,第二个索引是 1,按顺序以此依此类推。
list4 = ['red', 'green', 'blue', 'yellow', 'white', 'black']
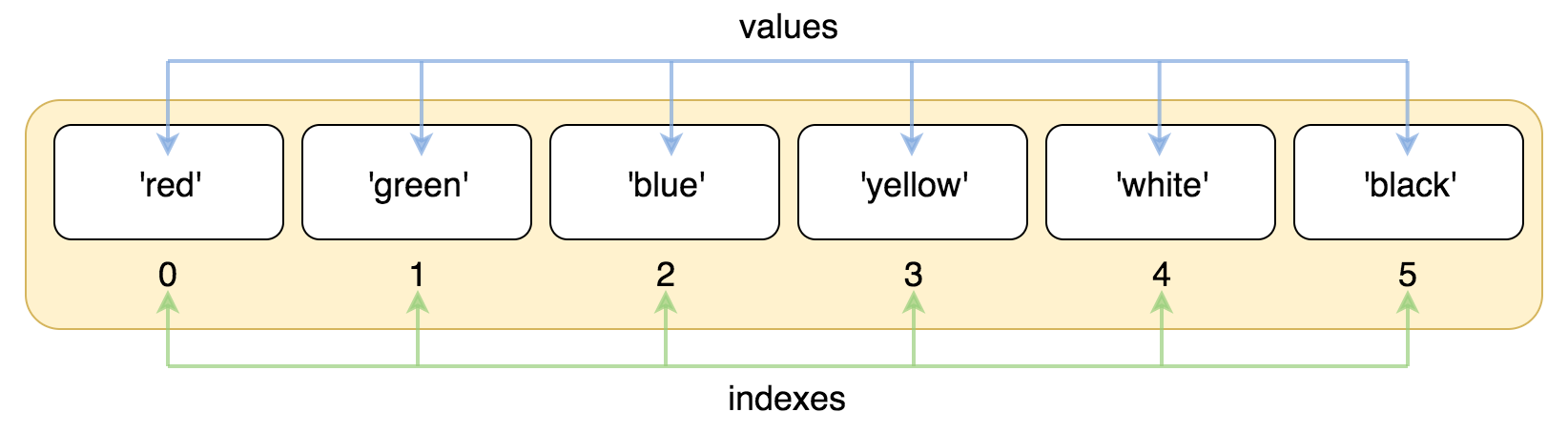
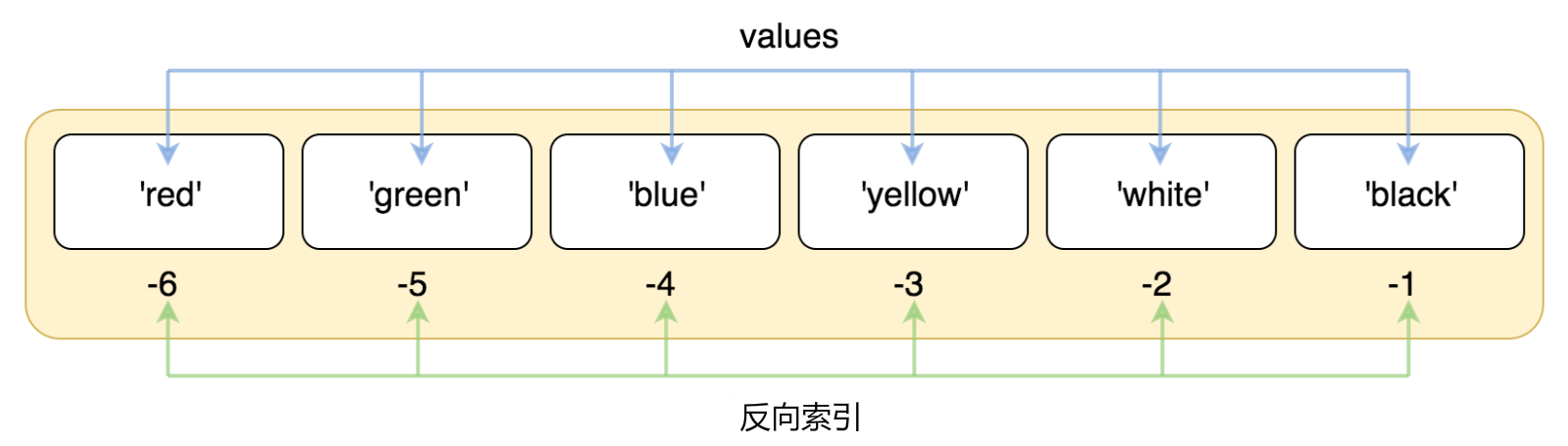
2.列表的基本操作#
列表的基础方法是索引访问和切片操作。索引访问是在列表对象后以list[index]进行访问单个元素。切片(slicing)提供了一种简洁高效的方式访问列表的特定部分,基本语法是list[start:stop:step]。
start:起始索引(闭区间),默认为0。
stop:结束索引(开区间),默认为序列长度
step:步长(可选),默认为1
注意三个参数在使用时可能会不输入,使用默认值
2.1 访问元素#
fruits = ["apple", "banana", "cherry", "date"]
#一、索引访问
# 正向索引(从0开始)
print(fruits[0]) # "apple"
print(fruits[2]) # "cherry"
# 负向索引(从-1开始)
print(fruits[-1]) # "date"
print(fruits[-2]) # "cherry"
#切片访问
#不填参数,默认输出整个序列
print(fruits[:]) #["apple", "banana", "cherry", "date"]
# 加入范围参数stop,访问多个值
print(fruits[1:3]) # ["banana", "cherry"]
print(fruits[:2]) # ["apple", "banana"]
# 加入范围参数step,访问多个值
nums = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print(nums[::2]) # [0, 2, 4, 6, 8] - 每隔一个取一个
print(nums[1::2]) # [1, 3, 5, 7, 9] - 从索引1开始每隔一个
2.2 修改列表#
列表中的元素是可以被修改的,你可以直接替换某个位置的元素,也可以一次替换多个元素。下面通过两个例子来看看如何修改列表。
修改单个元素:通过指定元素的索引(位置编号)来直接赋值,就能将旧元素替换成新元素。注意,索引是从0开始计数的。
修改多个元素(切片修改):通过指定一个索引范围(切片),可以一次替换该范围内的所有元素。新提供的元素列表长度可以和原切片长度不同,这会导致列表总长度发生变化。
fruits = ["apple", "banana", "cherry"]
# 修改单个元素
fruits[1] = "blueberry"
print(fruits) # ["apple", "blueberry", "cherry"]
# 修改切片
fruits[0:2] = ["apricot", "blackberry"]
print(fruits) # ["apricot", "blackberry", "cherry"]
2.3 添加元素
#
我们可以使用几种不同的方法来向列表中添加新的元素,它们各有用途:
append():在列表的末尾添加一个新元素。这是最常用的添加元素的方法。extend():在列表的末尾添加多个新元素。你可以把它理解为用一个新列表来“扩展”原有的列表。insert():在列表的任意指定位置插入一个新元素。你需要提供两个信息:要插入的索引和要插入的值。
numbers = [1, 2, 3]
# append() - 在末尾添加单个元素
numbers.append(4)
print(numbers) # [1, 2, 3, 4]
# extend() - 添加多个元素(扩展列表)
numbers.extend([5, 6])
print(numbers) # [1, 2, 3, 4, 5, 6]
# insert() - 在指定位置插入元素
numbers.insert(2, 99) # 在索引2处插入99
print(numbers) # [1, 2, 99, 3, 4, 5, 6]
2.4 删除元素
#
列表中的元素也可以被删除。Python提供了几种方法来删除元素,你可以根据不同的情况来选择:
remove():根据元素的值来删除。它会找到列表中第一个与指定值相等的元素,并将其删除。如果列表中有多个相同的值,只有第一个会被删除。pop():根据元素的索引(位置)来删除。它会删除指定位置的元素。如果不指定索引,pop() 会默认删除并返回列表的最后一个元素。clear():一次性删除列表中的所有元素,使其变成一个空列表。
numbers = [1, 2, 3, 4, 5, 6, 3]
# remove() - 删除第一个匹配的元素
numbers.remove(3)
print(numbers) # [1, 2, 4, 5, 6, 3]
# pop() - 删除并返回指定位置的元素
numbers.pop(1) # 删除索引1的元素
print(numbers) # [1, 4, 5, 6, 3]
# clear() - 清空列表
numbers.clear()
print(numbers) # []
2.5 查找和统计
#
我们可以检查列表中的元素,比如找到某个元素的位置、计算它出现了多少次,或者简单地判断它是否存在。Python为这些常见操作提供了简单的方法:
index():在列表中查找某个值,并返回第一个匹配到的元素的索引(位置)。如果值不存在,程序会报错。count():统计某个值在列表中总共出现了几次。in运算符:这是一个快速检查的简便方法。它用于判断某个值是否存在于列表中,返回一个布尔值(True 表示存在,False 表示不存在)。
fruits = ["apple", "banana", "cherry", "apple", "date"]
# index() - 返回第一个匹配元素的索引
print(fruits.index("banana")) # 1
# count() - 统计元素出现次数
print(fruits.count("apple")) # 2
# in 运算符 - 检查元素是否存在
print("cherry" in fruits) # True
print("grape" in fruits) # False
2.6 排序和反转
#
我们经常需要对数字列表中的元素进行重新排列,例如按照大小排序或者反转顺序。Python 提供了两种排序方法和一种反转方法:
sort():这个方法会直接修改原来的列表,将其中的元素从小到大进行排序(升序)。通过设置参数 reverse=True,可以实现从大到小的降序排序。操作后,原列表的顺序就永久改变了。sorted():这是一个函数,它不会改变原来的列表。它会接收一个列表,然后返回一个全新的、排序好的列表。同样,可以用 reverse=True 参数来降序排序。reverse():这个方法会将列表中元素的顺序完全反转(第一个变最后一个,最后一个变第一个)。它也是直接修改原列表。
numbers = [3, 1, 4, 1, 5, 9, 2]
# sort() - 原地排序(修改原列表)
numbers.sort()
print(numbers) # [1, 1, 2, 3, 4, 5, 9]
numbers.sort(reverse=True) # 降序排序
print(numbers) # [9, 5, 4, 3, 2, 1, 1]
# sorted() - 返回新排序列表(不修改原列表)
original = [3, 1, 4, 1, 5]
sorted_list = sorted(original)
print(f"原列表: {original}, 排序后: {sorted_list}") #原列表: [3, 1, 4, 1, 5], 排序后: [1, 1, 3, 4, 5]
# reverse() - 反转列表
numbers.reverse()
print(numbers) # [1, 1, 2, 3, 4, 5, 9] 反转后
2.7 列表拼接和重复
#
我们用简单的运算符,将多个列表连接在一起,或者将一个列表重复多次。这是通过 + 和 * 运算符来实现的。
列表拼接 (+):使用加号 + 可以将两个或多个列表顺序连接,生成一个包含所有元素的新列表。此外,2.3中我们介绍过
extend()函数也具有此功能。列表重复 (*):使用乘号 * 可以将一个列表的内容重复指定次数,生成一个更长的、元素重复出现的新列表。这在需要初始化一个具有相同元素的列表时非常有用。
# 列表拼接
list1 = [1, 2, 3]
list2 = ['a', 'b', 'c']
combined_list = list1 + list2
print(combined_list) # 输出: [1, 2, 3, 'a', 'b', 'c']
# 列表重复
repeated_list = ['hello'] * 3
print(repeated_list) # 输出: ['hello', 'hello', 'hello']
numbers = [0] * 5
print(numbers) # 输出: [0, 0, 0, 0, 0]
# 混合操作
mixed = (list1 * 2) + list2
print(mixed) # 输出: [1, 2, 3, 1, 2, 3, 'a', 'b', 'c']
3.多维数组的操作
#
建议
多维数组的操作十分重要,后续深度学习的基础就是矩阵运算,像Numpy库和PyTorch都包含了大量的张量和向量运算。
在Python中,我们可以用列表的嵌套(即列表里面包含列表)来表示多维数组,最常见的是二维数组,可以把它想象成一个由行和列组成的“表格”或“矩阵”。对它们的操作,通常需要理解其“行”和“列”的结构。
对于更高维度的数组,其操作原理是相同的,核心在于理解嵌套的层级关系。我们可以把更高维的数组看作是层层嵌套的“容器”。
操作逻辑:无论数组有多少维,你都需要从外向内,逐层使用索引来定位。
array[i]: 获取三维数组的第 i 个“层”(即一个二维表格)。array[i][j]: 获取第 i 层的第 j 行(即一个一维列表)。array[i][j][k]: 获取第 i 层、第 j 行、第 k 列的具体元素值。
# 创建二维数组(矩阵)
matrix_2d = [
[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
]
print("二维数组:")
for row in matrix_2d:
print(row)
# 访问元素
print(f"\nmatrix_2d[1][2] = {matrix_2d[1][2]}") # 第2行第3列(索引从0开始)
# 创建三维数组
matrix_3d = [
[
[1, 2, 3],
[4, 5, 6]
],
[
[7, 8, 9],
[10, 11, 12]
]
]
print(f"\n三维数组形状: {len(matrix_3d)}x{len(matrix_3d[0])}x{len(matrix_3d[0][0])}")
print(f"matrix_3d[1][0][2] = {matrix_3d[1][0][2]}") # 第2个矩阵的第1行第3列
# 遍历三维数组
print("\n遍历三维数组:")
for i, matrix in enumerate(matrix_3d):
print(f"矩阵 {i}:")
for row in matrix:
print(f" {row}")
4.列表的复制
#
在复制列表时,有一个重要的概念需要区分:浅复制和深复制。它们之间的区别在于如何处理列表内部的子列表(或其他可变对象)。
浅复制问题:使用 copy() 方法或切片 [:] 进行的是“浅复制”。它只复制了列表的“外层”,如果列表里还有子列表,那么复制的是子列表的引用(可以理解为快捷方式),而不是创建全新的子列表。因此,修改浅复制后的子列表内容,原列表也会跟着改变,因为它们指向的是同一个子列表。
深复制:使用 copy 模块中的 deepcopy() 函数可以进行“深复制”。它会递归地复制列表及其内部所有子对象,创建一个完全独立的新列表。之后修改新列表的任何部分,都不会影响到原列表。
# 浅复制问题
original = [[1, 2], [3, 4]]
shallow_copy = original.copy() # 或 original[:]
shallow_copy[0][0] = 99
print(f"原列表: {original}") # [[99, 2], [3, 4]]
print(f"浅复制: {shallow_copy}") # [[99, 2], [3, 4]]
# 深复制
import copy
deep_copy = copy.deepcopy(original)
deep_copy[0][0] = 100
print(f"原列表: {original}") # [[99, 2], [3, 4]]
print(f"深复制: {deep_copy}") # [[100, 2], [3, 4]]
5.列表推导式
#
列表推导式是Python中一种非常简洁、强大的创建列表的方法。它可以用一行代码来代替多行循环,使代码更清晰易读。其基本思想是根据一个已有的序列(如列表、元组、range对象等),通过应用表达式和筛选条件,来生成一个新的列表。
创建新列表:列表推导式的核心是
[表达式 for 变量 in 序列]。它会遍历序列中的每个元素,用“表达式”处理该元素,然后将结果收集到一个新列表中。添加条件筛选:你可以在推导式末尾添加 if 条件,例如
[表达式 for 变量 in 序列 if 条件]。这样只会将满足条件的元素经过表达式处理后加入新列表。嵌套循环:列表推导式还可以包含多个 for 子句,用于实现嵌套循环。它按照从左到右的顺序执行循环,可以用来生成组合或创建多维结构。
range() 是 Python 内置函数,用于生成一个整数序列。它非常高效,因为它不会一次性创建所有数字,而是按需生成(惰性计算)。
# range示例
# 生成 3-7 的序列
for i in range(3, 8):
print(i) # 输出: 3 4 5 6 7
# 生成 2-10,步长为2
for i in range(2, 11, 2):
print(i) # 输出: 2 4 6 8 10
print(list(range(5))) # [0, 1, 2, 3, 4] 其中list()函数是用于类型转换
# 创建平方数列表
squares = [x**2 for x in range(10)]
print(squares) # [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
# 带条件的列表推导式
even_squares = [x**2 for x in range(10) if x % 2 == 0]
print(even_squares) # [0, 4, 16, 36, 64]
# 嵌套循环的列表推导式
pairs = [(x, y) for x in range(3) for y in range(3)]
print(pairs) # [(0,0), (0,1), (0,2), (1,0), ...]
6.列表操作的时间复杂度#
操作 |
时间复杂度 |
说明 |
|---|---|---|
索引访问 |
O(1) |
随机访问快 |
追加元素 |
O(1) |
平均情况 |
插入元素 |
O(n) |
需要移动后续元素 |
删除元素 |
O(n) |
需要移动后续元素 |
查找元素 |
O(n) |
需要遍历列表 |
切片 |
O(k) |
k是切片长度 |