1_1_什么是Python#
作者: ZhouLong
创建日期: 2026 年 01 月 10 日
版本: 1.0
浏览量:
1.编程语言基础#
编程语言可根据其抽象程度划分为不同层级,包括硬件层级、汇编层级、系统层级、应用层级和脚本层级。一般而言,上层语言通常依赖于下层语言实现,通过对底层功能进行封装和拓展,形成更强大的能力。 下层语言通常功能更为基础、开发复杂度较高,语法结构也相对接近机器逻辑,对人类而言不易直接理解。而经过逐层封装得到的高级语言,语法更贴近自然语言,功能更为丰富,显著降低了开发难度。

从执行方式来看,Python 属于解释型语言,C++ 属于编译型语言。解释型语言在运行过程中依赖解释器逐行将代码翻译为机器可执行的指令;而编译型语言在开发完成后需要预先经过编译过程,生成可直接由机器执行的二进制文件。
由于解释过程中需要实时翻译,解释型语言通常执行效率较低,运行速度一般慢于编译型语言。在典型场景中,C++ 的执行速度可比 Python 快数十倍。然而,在当前计算机硬件性能普遍较强的背景下,多数常见应用场景中用户难以直接感知这种速度差异。 此外,Python 的语法设计更贴近人类表达习惯,拥有丰富的标准库与第三方库支持,因此其开发效率通常高于 C++,开发周期更短。值得注意的是,如今许多 Python 科学计算库(如 NumPy、SciPy 等)底层核心由 C/C++ 实现并经过高度优化,在执行 计算密集型任务时,其性能已接近直接使用 C++ 编写的程序水平。
2.Python历史:从圣诞项目到全球狂欢#

诞生:一个程序员的圣诞假期(1989-1991)
1989年圣诞节,荷兰程序员吉多·范罗苏姆(人送外号龟叔)为了打发时间,决定创造一门新语言。他想要融合C语言的能力与ABC语言的简洁,将其命名为“Python”——灵感来自喜剧团体“蒙提·派森”。1991年2月,Python 0.9.0首次发布 ,已具备类、异常处理等核心特性。
成长:社区的力量(1990年代)
Python迅速吸引早期爱好者,1994年发布1.0版本。其“仁慈的独裁者”治理模式与活跃的comp.lang.python新闻组,形成了独特的协作文化。90年代末,Python开始被用于Google早期系统与NASA项目,证明了其实用性。
转折:勇敢的革新(2000-2008)
2000年Python 2.0引入垃圾回收和Unicode支持。但范罗苏姆意识到深层设计问题,于2008年推出不兼容的Python 3.0,彻底改革文本处理机制。这一决定虽导致长期的分裂与争议,却为未来发展扫清了障碍。
崛起:数据时代的王者(2010-2018)
NumPy(2005)、Pandas(2008)、scikit-learn(2010)等库的成熟,使Python成为数据科学的首选。结合Jupyter笔记本的交互体验,Python在人工智能浪潮中占据中心位置,2018年跻身TIOBE排行榜前三。
传承:新时代的开启(2019至今)
2019年范罗苏姆卸任后,Python由指导委员会集体领导。2020年Python 2正式退役,标志着一个时代的终结与统一。如今,Python继续在AI、Web开发、自动化等领域定义着“简洁力量”的传奇。
3.Python特点#
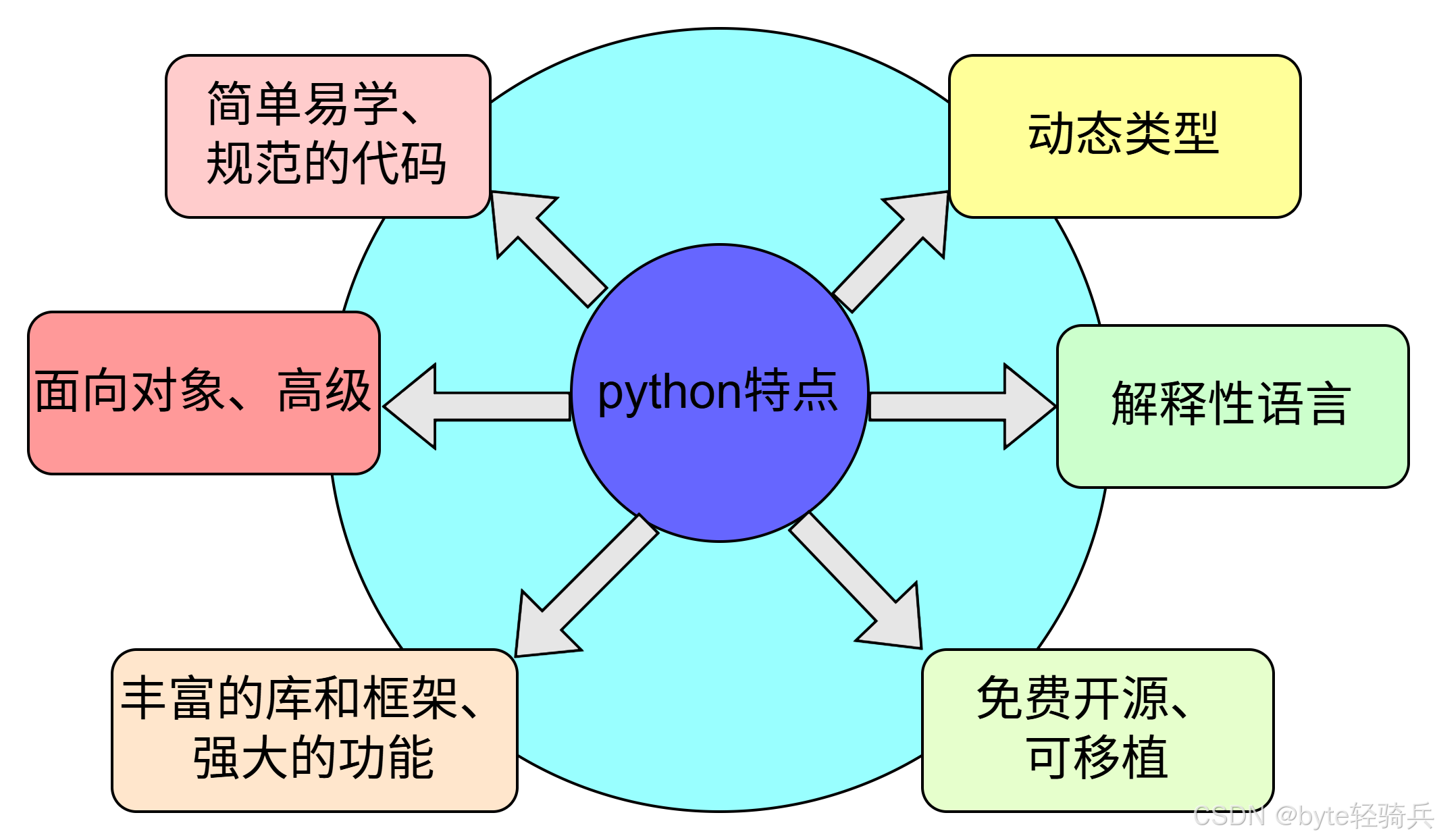
3.1 Python 优点#
1. 极致简洁的语法设计
Python 以 **“优雅、明确、简单”**为设计哲学,其语法非常接近自然语言,极大地降低了编程的入门门槛和维护成本。它通过强制缩进统一代码风格,减少了冗余符号(如大括号、分号),让开发者能更专注于逻辑而非语法细节。与 C++ 等系统级语言相比,Python 可以用少得多的代码完成同等功能的任务。
例如,实现一个简单的列表元素排序并输出,Python 与 C++ 的对比:
# Python
numbers = [5, 2, 8, 1, 9]
numbers.sort()
for num in numbers:
print(num)
// C++
#include <iostream>
#include <vector>
#include <algorithm>
int main() {
std::vector<int> numbers = {5, 2, 8, 1, 9};
std::sort(numbers.begin(), numbers.end());
for (int num : numbers) {
std::cout << num << std::endl;
}
return 0;
}
可以看到,Python 代码核心逻辑清晰直观,因而开发效率极高。
2. 蓬勃发展的生态系统
Python 拥有一个极其庞大且活跃的开源生态系统,这是其最核心的竞争力之一。
PyPI(Python Package Index):官方的第三方软件库仓库,目前托管超过 50 万个项目。开发者只需使用简单的
pip install package_name命令,即可轻松获取从 Web 框架、科学计算到机器学习、自动化脚本等几乎所有领域的工具库,如 Django, Flask, NumPy, Pandas, PyTorch, TensorFlow, Requests 等。Conda:一个流行的开源包管理和环境管理系统,尤其受到数据科学和科学计算社区的青睐。它不仅管理 Python 包,还能管理任何语言的包(如 R, C++库)和软件本身。其强大的环境隔离功能(
conda create -n myenv)允许用户为不同项目创建互不干扰的依赖环境。广泛的工具链与社区:生态的繁荣不仅体现在核心库上,还体现在丰富的辅助工具中,如代码格式化工具 Black、类型检查工具 MyPy、虚拟环境管理工具 venv/virtualenv、一站式开发环境 Jupyter Notebook 等。同时,Stack Overflow、GitHub 上海量的问答、教程和开源项目,确保了任何问题都能快速找到解决方案。
3. 卓越的跨领域适应性
Python 是一门真正的“多面手”语言,其应用场景几乎无所不包:
Web 开发:凭借 Django、Flask 等框架快速构建后端服务。
数据科学与机器学习:NumPy、Pandas、Scikit-learn、PyTorch、TensorFlow 等库使其成为该领域的事实标准语言。
自动化与脚本:简洁语法使其成为系统管理、任务自动化、测试脚本编写的首选。
网络爬虫:Requests、Scrapy、BeautifulSoup 等工具组合让数据抓取变得高效。
嵌入式脚本:广泛作为插件或脚本语言嵌入到 Maya、Blender、GIMP、Sublime Text 等大型应用中。 这种“一专多能”的特性,使得学习 Python 能够触达众多行业,投资回报率极高。
3.2 Python 缺点#
然而,世界上没有绝对完美的语言,否则程序员们就不会因为哪种语言是世界上最棒的语言而吵得不可开交。(其中不乏很多大佬相互开战)。
Python语言本身也有非常非常显著的缺点。
1. 性能瓶颈:解释型语言的根本约束
作为解释型语言,Python 代码在运行时由解释器逐行翻译并执行,而非像 C/C++ 或 Rust 那样直接编译为高效的机器码。这带来了固有的性能限制:
执行速度慢:在 CPU 密集型任务(如复杂的数学运算、大规模循环)中,Python 的执行速度通常比 C/C++ 慢数十倍甚至上百倍。
内存消耗大:Python 对象(如列表、字典)为了提供动态类型的灵活性,包含大量的元数据(如类型信息、引用计数),导致内存占用远高于存储纯数据本身。在处理海量数据时,内存开销可能成为瓶颈。
启动开销:启动 Python 解释器和加载大型模块有一定的时间开销,对于需要极速启动的短生命周期工具或命令行程序来说不太理想。
2. 全局解释器锁(GIL)的多线程困境
GIL是 CPython(Python 官方解释器)中的一个互斥锁,它规定在任意时刻,只有一个线程可以执行 Python 字节码。这意味着:
无法充分利用多核CPU:对于计算密集型(CPU-bound)的多线程程序,即使有多个 CPU 核心,线程也无法并行执行,性能无法随核心数线性增长,甚至可能因为锁竞争而更差。
解决方案与限制:为了进行并行计算,开发者通常需要采用多进程(
multiprocessing模块)而非多线程,但这会带来更高的内存开销和进程间通信成本;或者使用asyncio进行异步 I/O 密集型并发;亦或将关键部分用 C 扩展实现并释放 GIL。GIL 的存在使得编写高性能的并行 Python 程序变得复杂和间接。
3. 包管理与部署的复杂性
尽管 Python 的包管理工具强大,但也因其灵活性带来了显著的复杂性挑战:
依赖与版本冲突:不同库可能依赖同一库的不同版本(如同时要求
numpy<1.9vsnumpy>2.0,则会报错)。当项目依赖关系复杂时,在复现项目,配置环境时仍可能遇到难以解决的依赖冲突问题。工具与工作流碎片化:Python 生态中存在多种包管理和打包工具(
pip,pipenv,uv,poetry,conda,setuptools,wheel等),每种工具都有其配置文件和实践(如setup.py,pyproject.toml,requirements.txt,environment.yml)。对于新手而言,选择合适的工具链并正确配置是一大挑战。